昨天我們已經把文字轉成向量了
這邊再來介紹一下向量還有專門存向量的向量資料庫
向量資料庫這一年因為LLMs的關係飛速成長,
目前還在戰國時代,沒有哪個特別突出
但不建議用太新的,雖然很新很酷但範例會少很多
或許再過一段時間就會跟sql一樣固定幾個知名的
處理大量資料變得非常重要,尤其是在需要使用大型語言模型(Large Language Models)、生成式AI或語義搜尋(semantic search)、相似搜尋的程式中。其中因為有超過80%的資料是非結構化的
結構化資料是指採用標準化格式、具有明確定義的結構、符合資料模型、遵循長久規範、容易被人類和程式存取的資料
其他則是非結構化資料常見的如下列所示
向量資料庫是用來快速找到相似項目的工具。它能夠將物件轉換為數字向量,並根據向量的相似度比較找到最相似的項目。這在圖像搜尋、推薦系統和分類任務中非常有用。它能夠讓我們高效處理大量資料並找到相似的項目。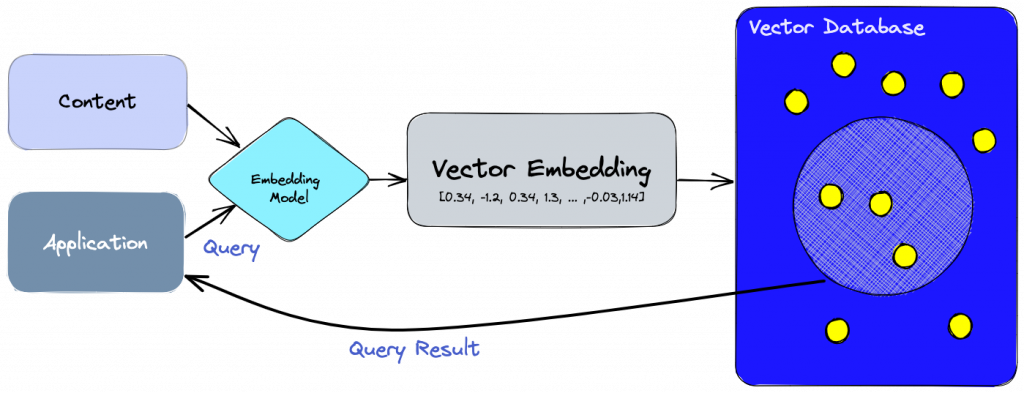
安裝超級方便,跟傳統sql不一樣
隨裝及用,安裝過程就跟平常安裝套件一樣
裝完也不用再設定什麼可以直接做使用
新增資料、查詢資料進去也超級簡單,沒什麼查詢語法
資料 -> embedding -> 向量存進向量資料庫 -> 需要使用時做向量搜尋
有更多疑問歡迎留言或來群組跟大家一起討論 : https://discord.gg/sFDuct738y
參考:
https://www.youtube.com/watch?v=dN0lsF2cvm4
https://www.pinecone.io/learn/vector-database/
https://www.tibco.com/zh-hant/reference-center/what-is-structured-data

